Hello there.
My name is Daniel Wetzel.
By day, I help businesses harness the power of AI,
and by night, I work on projects I find cool and interesting...
whether it's exploring new tech or just building something fun.

By day, I help businesses harness the power of AI,
and by night, I work on projects I find cool and interesting...
whether it's exploring new tech or just building something fun.

Let us start with a little introduction...
During my Master's at TU Berlin, I took a deep dive into the environmental side of AI, focusing on how to deploy
large language models more energy-efficiently (because saving the planet while building cool tech is a win-win, right?).
Now, I bring that balance of innovation and sustainability to my work at Deloitte.

Exploring how to reduce energy consumption in LLMs without sacrificing performance.
In my Master's thesis at TU Berlin, I tackled a pressing issue in the AI world: how to make large language models (LLMs) more energy-efficient. With AI models growing larger and more energy-hungry, it's crucial to find ways to cut down on energy use without compromising on quality (because saving the planet while building cool tech is a win-win, right?).
Model Generation appears to be one of the most efficient ways to improve performance and efficiency. With each new generation, models become significantly better at the same size, emphasizing the importance of flexibility in use cases to allow for quick model updates.
While it is fun, Fine-Tuning should still be ones last resort due to its lack of flexibility compared to other optimization techniques. Instead, building a pipeline with knowledge embedding and effective system prompts allows for easier model replacement with minimal effort.
I've put together an interactive Streamlit dashboard where you can explore the findings, play around with different configurations, and see how these optimizations can save energy. Otherwise, you could also check out my full master's thesis.
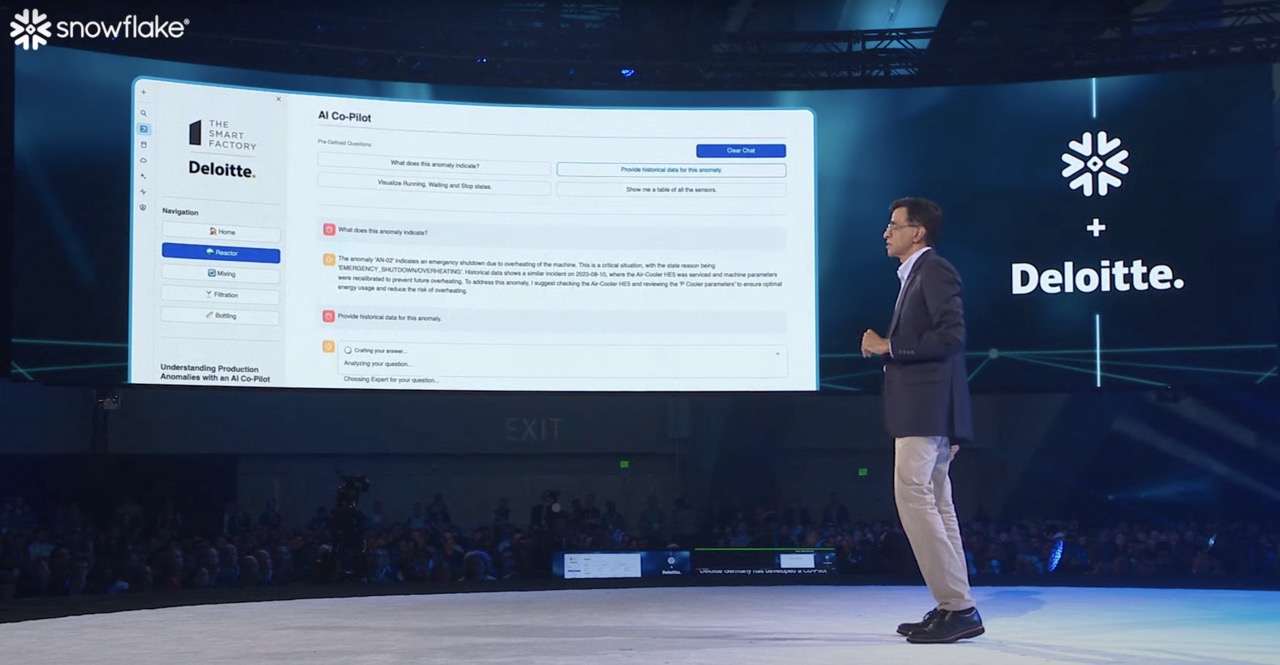
Revolutionizing Manufacturing Intelligence through Snowflake's advanced Capabilities.
(Highlighted at Snowflake Summit 2024)
The Snowflake Smart Factory PoC was designed to demonstrate the powerful capabilities of Snowflake within a Smart Manufacturing context at the Hannover Messe 2024 (HMI2024).
The core of the application revolves around Snowflake's Cortex AI Features. These included Document AI to extract information from factory incident reports. This data is then vectorized using Snowflake's embeddings model and stored in a vector database. Utilizing Snowflake's similarity search feature we could then retrieve useful historical information for current anomalies.
In parallel, we ingested sensory data from four factory machines in near real-time using Snowpipes. This data was then cleaned and transformed for immediate use in the application's visualizations, providing live insights into the factory's operations. The entire application is built on Streamlit, hosted natively within Snowflake.
Our AI assistant is built on a multi-agent processing pipeline, utilizing open-source models such as various LLaMA and Mistral versions. The pipeline detects user intent with a lightweight model and selects the most suitable agent for the task, enabling the selective use of larger models only when necessary. Each agent is enhanced with Retrieval-Augmented Generation (RAG) style knowledge embedding, allowing the assistant to provide detailed insights into current anomalies, enriched by historical data from unstructured PDF incident reports.
Moreover, the assistant can dynamically generate visualizations and tables based on the user's queries, utilizing regex pattern matching through the respective agents. The entire processing pipeline was built natively in Python and Streamlit (without LangChain). This approach emphasizes the application’s suitability for production environments with strict library restrictions, security concerns, and performance optimization requirements.

Developing a Python library to interface with DAPHNE's C++ backend, enabling seamless data exchange and integration with popular data science libraries.
The DAPHNE project aims to define and build an open and extensible system infrastructure for integrated data analysis pipelines. This includes data management and processing, high-performance computing (HPC), and machine learning (ML) training and scoring. The project covers several areas, such as system architecture, hardware utilization, scheduling improvements, benchmarking, and real-life use cases, all aimed at improving productivity and performance in large-scale data management.
DAPHNE uses a domain-specific language (DSL) called DaphneDSL to execute its performant Data Engineering, Science, and Analytics tasks. However, Python is the most popular language in these domains with a vast ecosystem of libraries and tools, making it impractical for Data Scientists to switch to DaphneDSL. Thus, DAPHNE needs a robust Python API, which provides DAPHNE's operations in Python while maintaining DAPHNE's performance. A basic version of this API already existed prior to the project but it lacked seamless integration into the Python-based data science ecosystem. To achieve this goal, efficient data exchange between DaphneLib and established Python libraries such as numpy, pandas, TensorFlow, and PyTorch was needed.
The project required efficient data transfer between DaphneLib and Python libraries without relying on file-based transfers, which are inefficient. Instead, we focused on shared memory and zero-copy data exchange to maintain performance. This means that we had to share memory addresses between the C++ and Python processes, which is a non-trivial task. Additionally, we had to integrate custom garbage collection in communication between Python and DAPHNE to prevent memory leaks.
Memory Management
It was a significant challenge to prevent memory overflow as the transferred objects were referenced both in Python and C++
and were therefore not deleted by their respective garbage collectors.
Ultimately, the Python interpreter had no information if the object was referenced by DAPHNE and vice versa.
Data Handling in Python
Ensuring zero-copy behavior in Python is quite difficult. Many libraries offer copy operations and in-place operations.
Sometimes it is as simple as adding a parameter like "inplace=True"; other times, different functions are needed for in-place operations.
In the worst case, the behavior is chosen by the function you are using automatically, making the result unpredictable.
Preserving Object Integrity
DAPHNE did not offer support for DataFrames and Tensors at the time of the project.
Therefore, we had to ensure that none of the information was lost during the transfer.
To achieve this, we flattened multi-dimensional tensors and stored the metadata of their original shapes in separate objects.
Furthermore, we stored DataFrames in 2D matrices while also keeping the index data and table metadata in separate objects.
Leading a team to develop a startup idea and business plan for a meaningful social connection app.
Moving to a new city can be tough. How do you find friends with a similar vibe? How do you discover events that match your interests? Despite the rise of social media and dating apps, many people still feel isolated. Platforms like Facebook or Instagram haven't solved the issue of building deeper connections. During and after the COVID-19 pandemic, this became even more evident. Social interactions often became superficial, making it harder to find like-minded people and attend events together.
Apps like Tinder or even Bumble for Friends try to help but often focus too much on dating. Matches are based on profile pictures and basic info, not shared interests, leading to uninspiring meetups. Newby addresses this challenge by focusing on matching people based on common interests and events.
Newby allows users to create groups for existing events, share new events, and find companions or join others' events. It offers a platform for discovering like-minded individuals and interesting activities, enhancing social experiences through shared interests.
The app includes features like event categorization, community creation, participant matching, and gamification to keep users engaged. Security is a priority, with only verified users allowed to create events or request to join. Users can personalize their homepage based on their interests and get tailored recommendations. Event organizers can also specify participant criteria to ensure compatibility.
Newby's monetization strategy revolves around the valuable data we gather. Users specify which events they attend and their preferences, along with providing demographic information. This allows us to comprehensively understand the event market in a city like Berlin, including traffic trends and user group interests.
With this data, we can offer promoted listings in our app. Event organizers can promote their events to specific demographics, ensuring targeted advertising. Additionally, smart matching can be used to advertise promoted events to the most ideal audience. In later stages, we can sell detailed market analysis to event managers, offering insights on current trends and optimal marketing strategies.
Managing a product team to tackle the "Smart Circular Kitchen" challenge as part of the InnoDays Spring 22.
The challenge aimed to find innovative solutions to combat food waste, a major issue where a substantial amount of edible food is discarded due to forgetfulness or poor management. Our target demographic included tech-savvy individuals and families who are concerned about food waste and lead busy lifestyles that often result in expired food items.
Since smart fridges are expensive and not widely accessible, we envisioned a more affordable alternative. Our solution was a small IoT device that can be attached to any cabinet or fridge, providing a practical and accessible way to track groceries. This device uses a camera and image detection technology to automatically monitor food items and their expiration dates. For fresh items without expiration dates, it leverages a food expiration time database.
Our companion app offers a comprehensive view and management of the tracked groceries. It also educates users on food expiration, helping them identify when food is still safe to eat, thereby reducing unnecessary waste.
I developed a fully interactive prototype of the MyPantry app, which is demonstrated in the video. The prototype showcases its capability to scan both packaged foods with printed expiry dates and fresh produce without them. By using a backend food database, the app predicts typical expiry dates for fresh items based on storage conditions. Additionally, it provides users with valuable information on how to detect expired food items, addressing the issue of good food being discarded unnecessarily.

Prediction of 7 human emotions with different neural networks and a dataset of 28.709 faces as grayscale pictures.
To solve the task, I have developed and tweaked a Convolutional Neural Network and compared it to two pre-defined networks (LeNet & VGG16). Since 1 emotion was drastically underrepresented in the dataset, I included an image augmentation algorithm to reduce overfitting. This algorithm rotated and shifted the images with the underrepresented emotion to create further trainings data. Nevertheless, the CNN only achieved an accuracy of around 60%. Even with the augmentation, the dataset was far from ideal making it nearly impossible to achieve better results.

Giving answers to questions based on Wikipedia articles utilizing the Stanford Question Answering Dataset (SQuAD) and the Google NLP model BERT.
The developed Chat-Bot had the task to find answers to given question within Wikipedia passages. To accomplish that, the Stanford dataset SQuAD was used which consists of over 100.000 Questions for over 500 Wikipedia articles. While working in student groups of 3, we had to analyze and understand the dataset first before we could start with an implementation. The initial idea was to build and train an own NLP model for the task. Yet, after some initial trial and error we realized that it was not possible to build a model remotely comparable to Google's pre-trained model BERT with the limited time and resources we had. Therefore, we decided to implement and train the BERT model for our use case. To do that, we had to completely transform our dataset from a json structure to a meaningful data frame. We tokenized, normalized & flagged the dataset and created an attention mask for the model.
Afterwards we trained our BERT model with the cleaned up dataset and Google Colabs hardware acceleration. At the end, we achieved an accuracy of over 80 percent with the possibility to add our own text examples. Even with those added examples the model was able to correctly answer our questions.
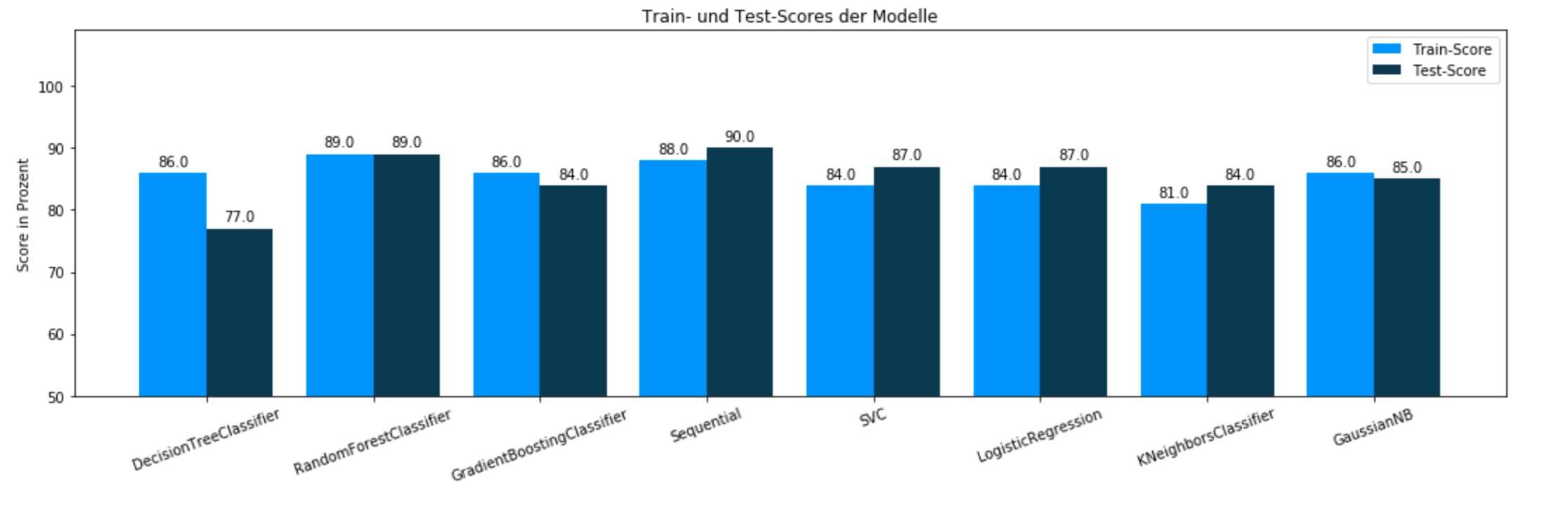
Prediction of cardiac diseases based on 14 features with a comparison of different machine learning models.
This project was done in a student group of 5 participants with a dataset from the Cleveland University. Its aim was to reliably predict cardiac diseases with a ML model based on a number of 14 patient features. To accomplish that, we decided to compare the accuracy of different models:
First we visualized selected aspects of the data to find first correlations and handled outliers as well as invalid or missing data. Afterwards, we scaled and normalized the data for models that require transformed data. Finally, we visualized the results to compare the models and came to a maximum accuracy of 89% with a RandomForest Classifier.